Clouhouse hat bestätigt, dass die Sicherheitslücke in der Verschlüsselungstechnologie lag, die verwendet wurde, um die Daten der Kunden zu schützen. Die Hacker haben es geschafft, diese Verschlüsselung zu umgehen und Zugang zu den Kundendaten zu erlangen. Das Unternehmen hat betont, dass keine Zahlungsinformationen oder Kreditkarteninformationen betroffen sind, da diese auf separaten Servern gespeichert werden.
Der führende Cybersecurity-Experte Jiten Jain berichtet, dass die komplette Datenbank der Clubhouse-Telefonnummern im Darknet zum Verkauf steht.
Die Datenbank enthält Informationen…
über 3,8 Milliarden Telefonnummern sowohl von Clubhouse-Mitgliedern als auch von Nutzern aus deren synchronisierten Kontaktlisten.
Das Unternehmen arbeitet derzeit eng mit Behörden und Cyber-Sicherheitsfirmen zusammen, um das Ausmaß des Datenlecks zu ermitteln und den Schaden zu minimieren. Kunden werden aufgefordert, ihre Passwörter zu ändern und sich an den Kundensupport zu wenden, um weitere Informationen zu erhalten.
Dieses Datenleck ist ein weiteres Beispiel dafür, wie wichtig Datenschutz und Cyber-Sicherheit in der heutigen digitalen Welt sind. Unternehmen müssen sicherstellen, dass ihre Verschlüsselungstechnologie sicher und robust ist und regelmäßig aktualisiert wird, um den neuesten Bedrohungen standzuhalten. Kunden sollten auch sicherstellen, dass sie starke Passwörter verwenden und diese regelmäßig ändern, um ihr Konto vor Hackern zu schützen.
Es bleibt abzuwarten, welche Auswirkungen dieses Datenleck auf Clouhouse und seine Kunden haben wird. In der Zwischenzeit sollten Unternehmen und Kunden gleichermaßen die Bedeutung von Datenschutz und Cyber-Sicherheit im digitalen Zeitalter ernst nehmen und sich bewusst sein, dass niemand vor Datenmissbrauch und -verlust gefeit ist.

Höchstwahrscheinlich stehen Ihre Daten auch dann auf der Liste, wenn Sie noch keinen Zugang zu Clubhouse hatten, so Jain.
Clubhouse dementiert angebliche Datenpanne
Die reine Audioplattform behauptet, Bots würden zufällige Telefonnummern generieren
In einer Erklärung gegenüber einer indischen Nachrichtenagentur dementiert Clubhouse das Datenleck von über 3,8 Milliarden Mobilfunknutzern, die mit der Plattform verbunden sind. Clubhouse sagt, dass “es eine Reihe von Bots gibt, die Milliarden von zufälligen Telefonnummern generieren” und “eine dieser zufälligen Nummern zufällig auf unserer Plattform existiert, aufgrund eines mathematischen Zufalls.” Darüber hinaus erklärte Clubhouse, dass die API des Unternehmens keine Informationen zur Identifizierung der Nutzer liefert.
Clubhouse ist ein beliebtes soziales Netzwerk, in dem Menschen zusammenkommen, um in Echtzeit zu chatten, zuzuhören und voneinander zu lernen. Seit seiner Einführung im März 2020 ist Clubhouse eine App, die nur für geladene Gäste zugänglich ist. Am 21. Juli dieses Jahres hat das Unternehmen die Einladungsoption entfernt und die App für alle Nutzer auf iOS- und Android-Plattformen verfügbar gemacht.
Lesen Sie mehr:
- https://twitter.com/mruef/status/1418693478574346242
- https://www.republicworld.com/technology-news/apps/clubhouse-data-leak-voice-chat-app-denies-3-dot-8bn-phone-numbers-were-released-on-dark-web.html
- https://www.firstpost.com/tech/news-analysis/clubhouse-denies-allegation-of-data-breach-that-claimed-to-leak-3-8-million-phone-numbers-on-dark-web-9837851.html
Clouhouse hat bestätigt, dass die Sicherheitslücke in der Verschlüsselungstechnologie lag, die verwendet wurde, um die Daten der Kunden zu schützen. Die Hacker haben es geschafft, diese Verschlüsselung zu umgehen und Zugang zu den Kundendaten zu erlangen. Das Unternehmen hat betont, dass keine Zahlungsinformationen oder Kreditkarteninformationen betroffen sind, da diese auf separaten Servern gespeichert werden.
Der führende Cybersecurity-Experte Jiten Jain berichtet, dass die komplette Datenbank der Clubhouse-Telefonnummern im Darknet zum Verkauf steht.
Die Datenbank enthält Informationen…]]>
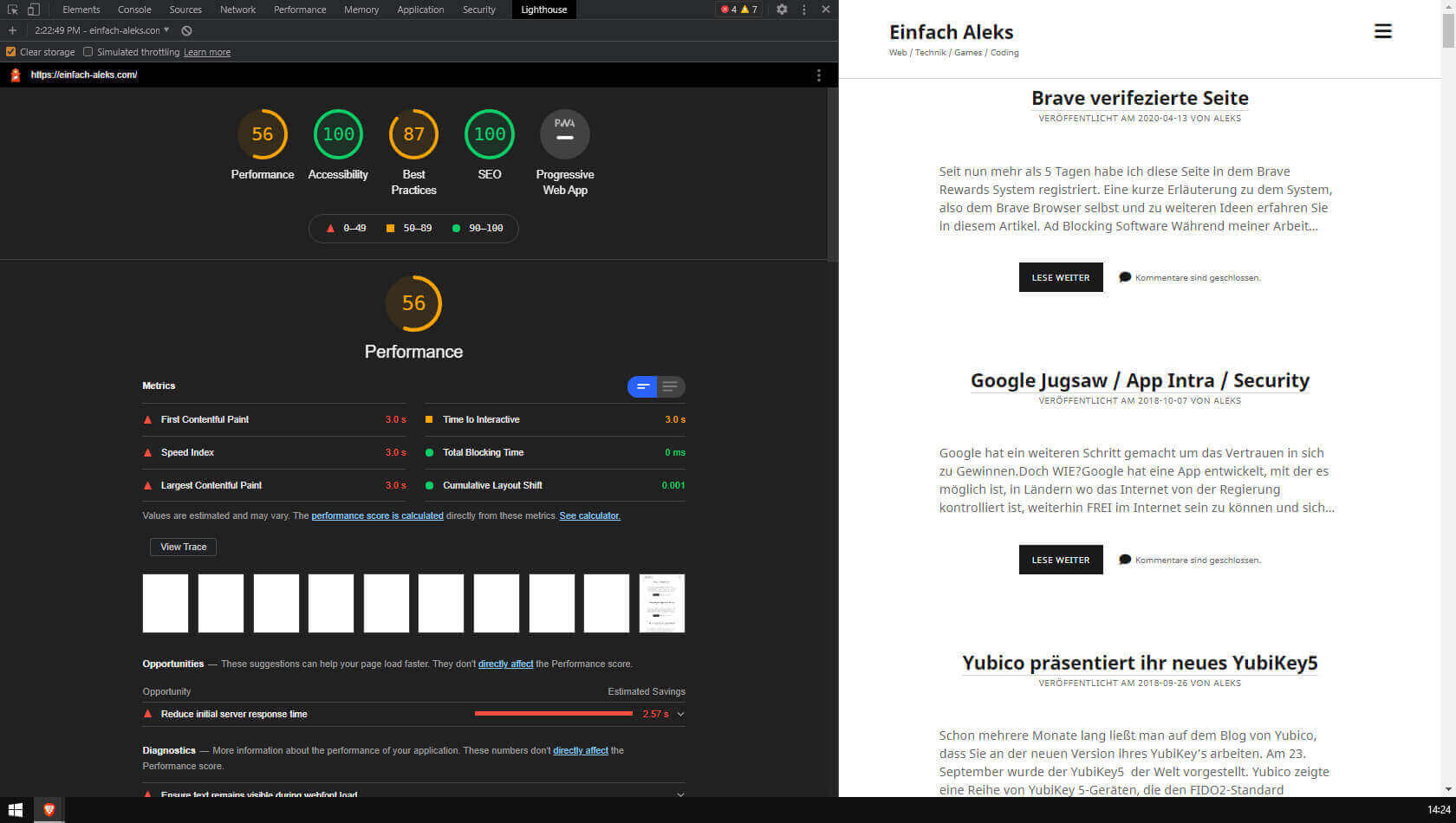
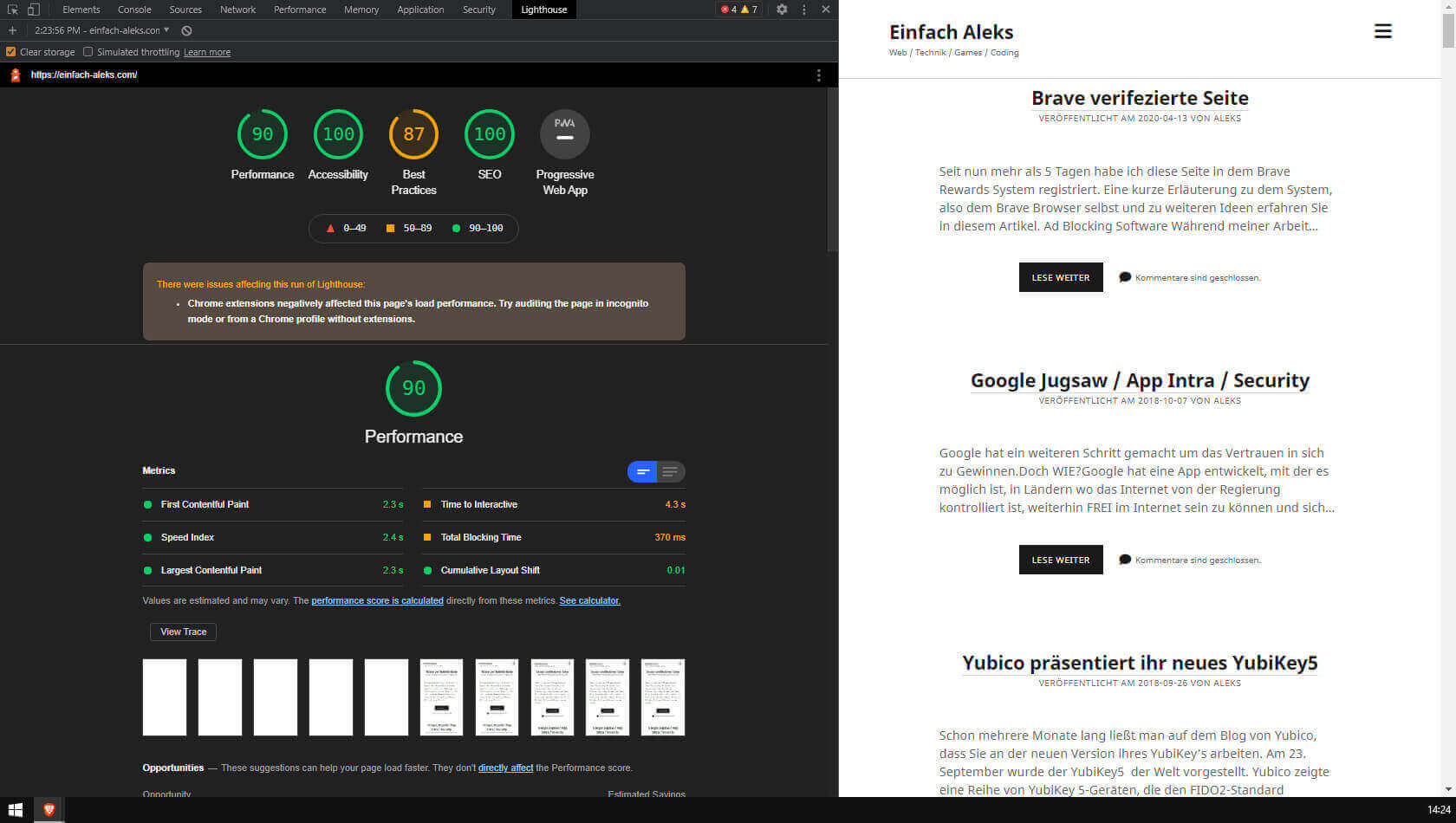
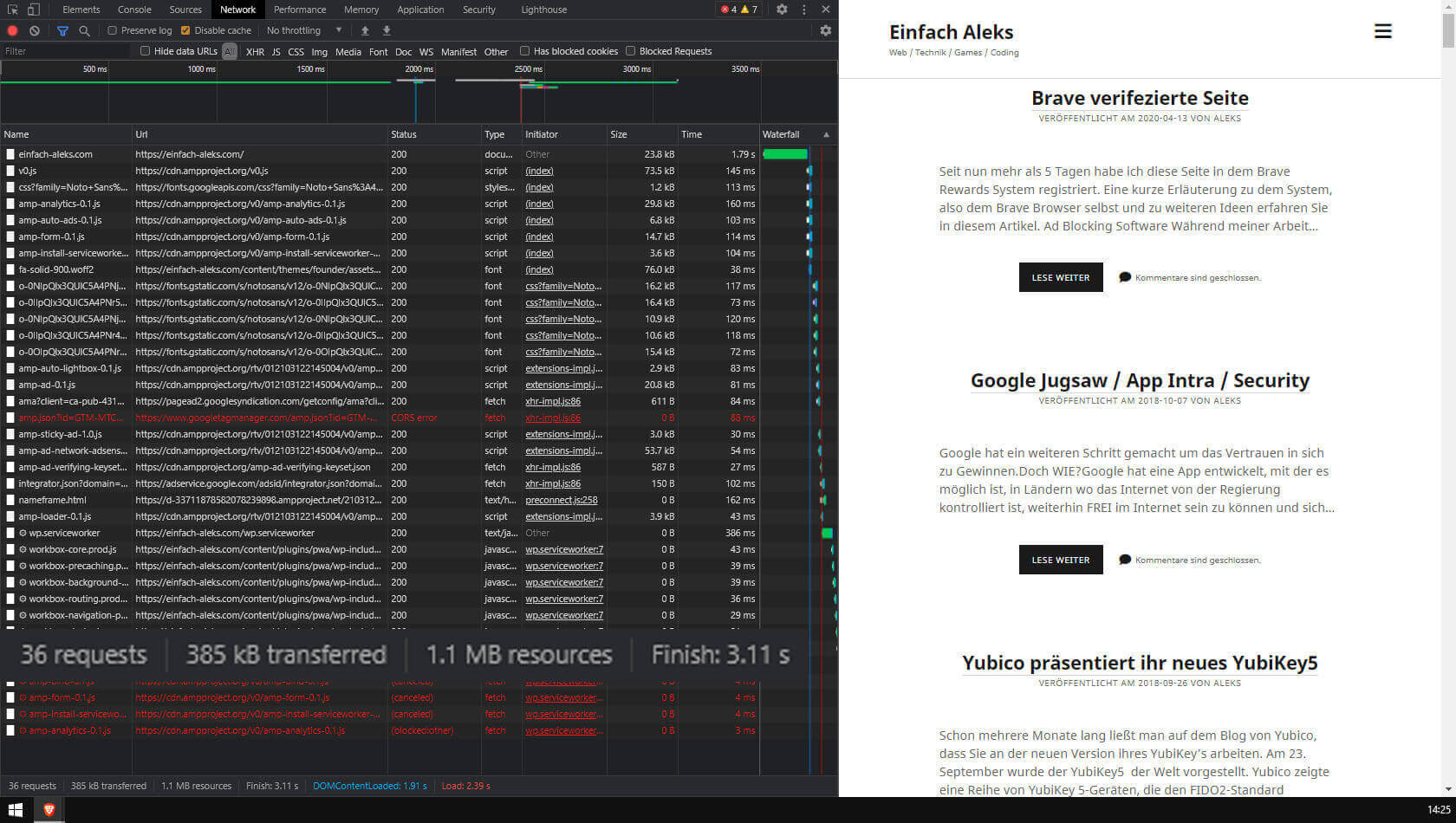
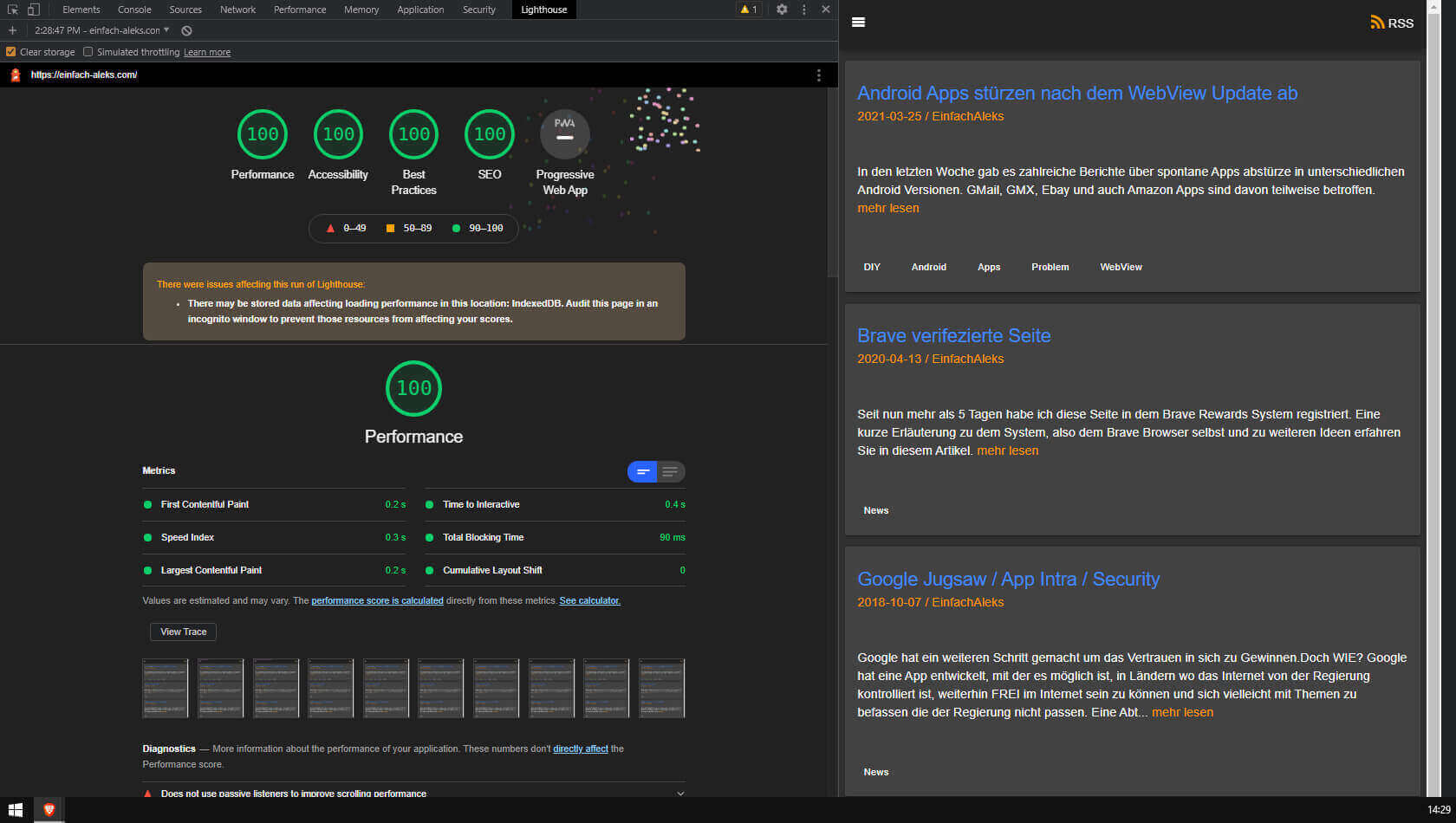
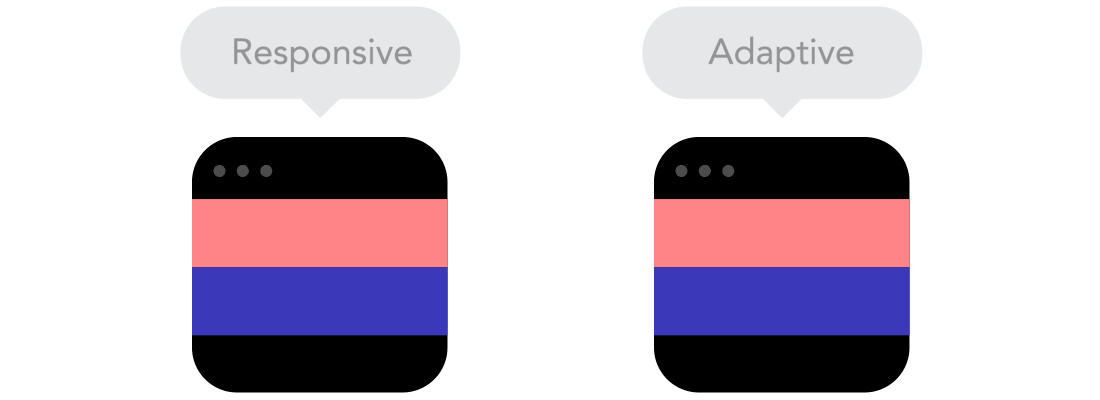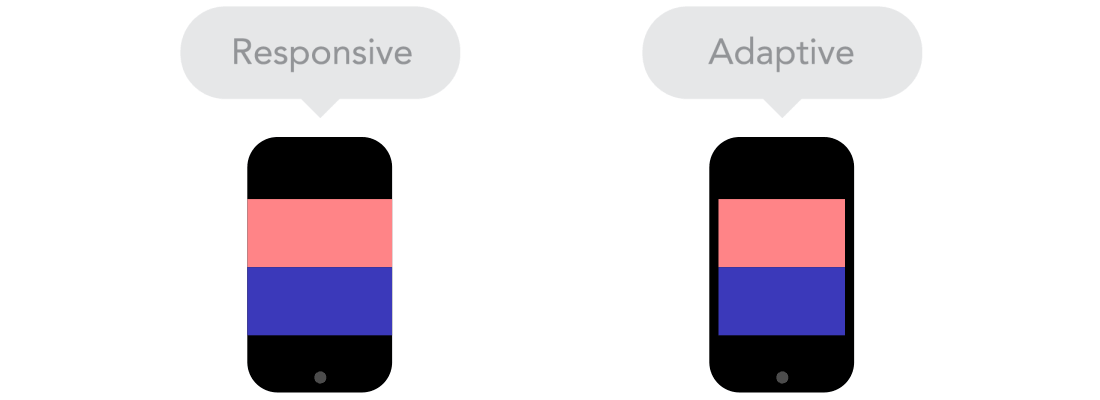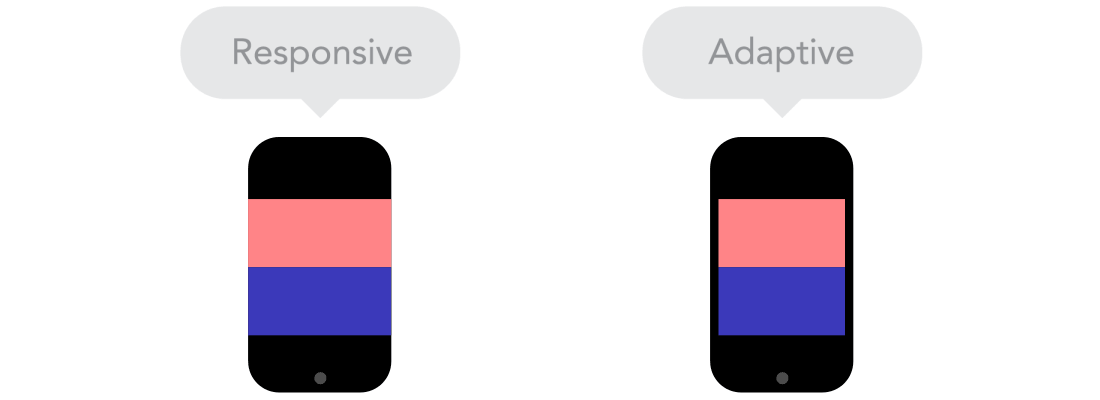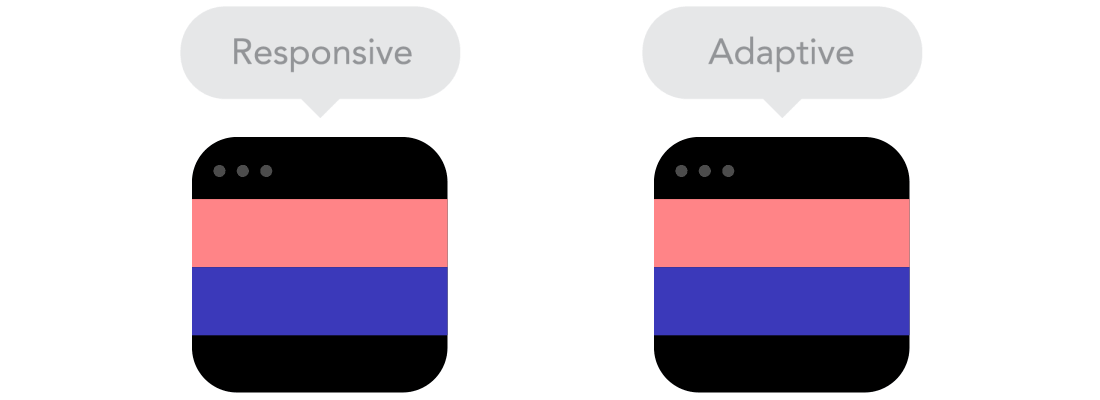 Flow
Flow 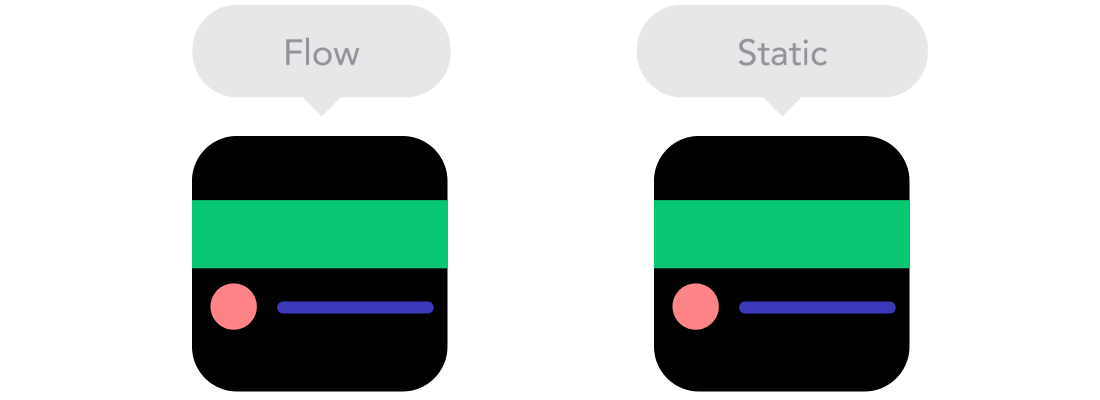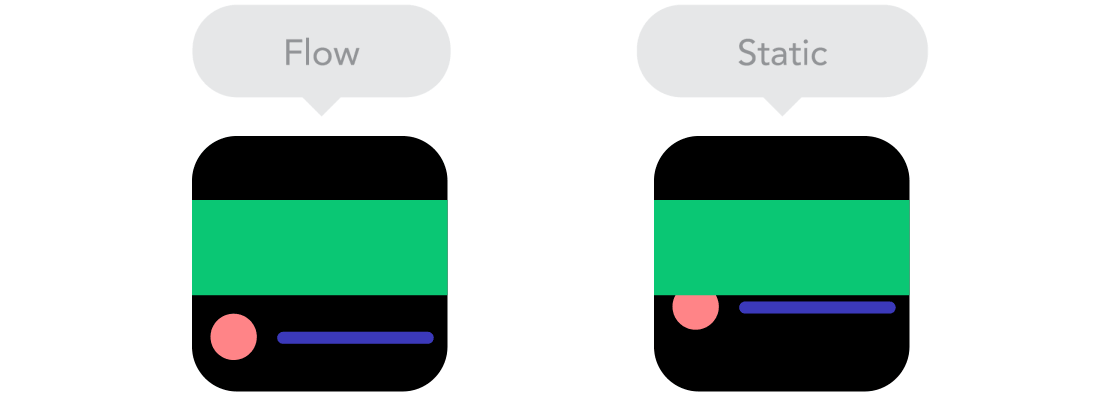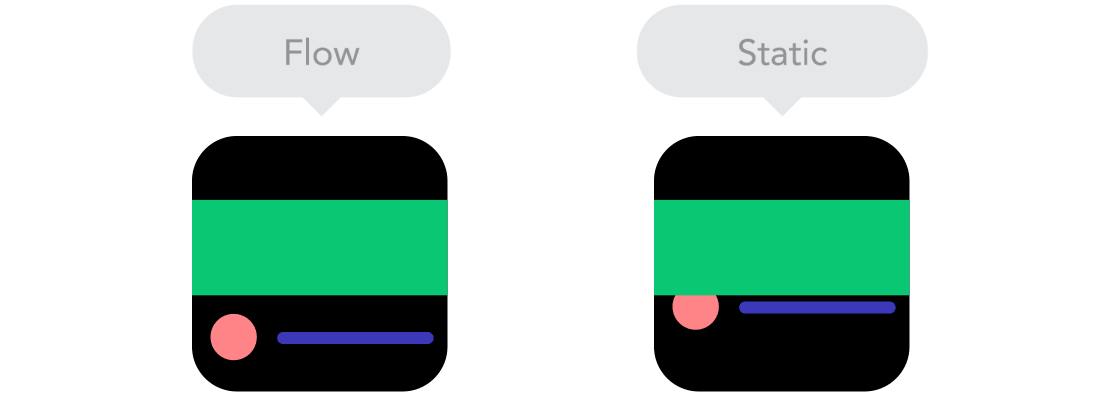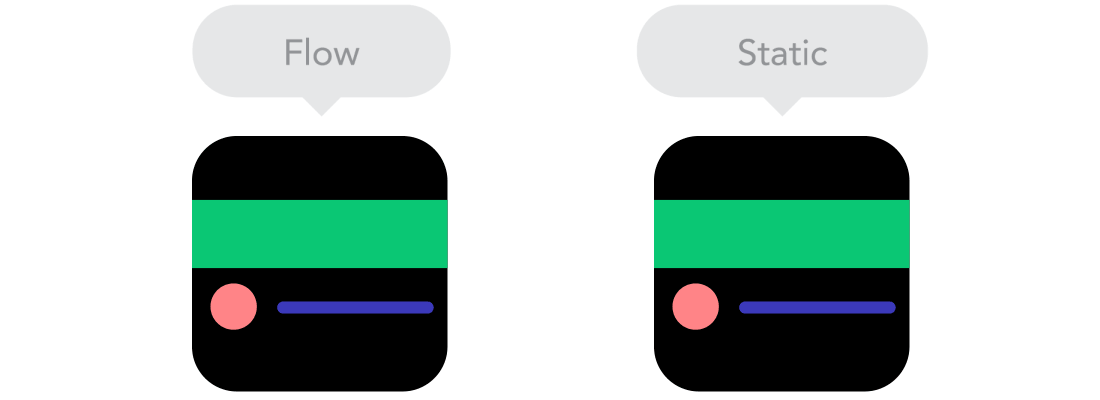 Relative Units vs Static Units
Relative Units vs Static Units 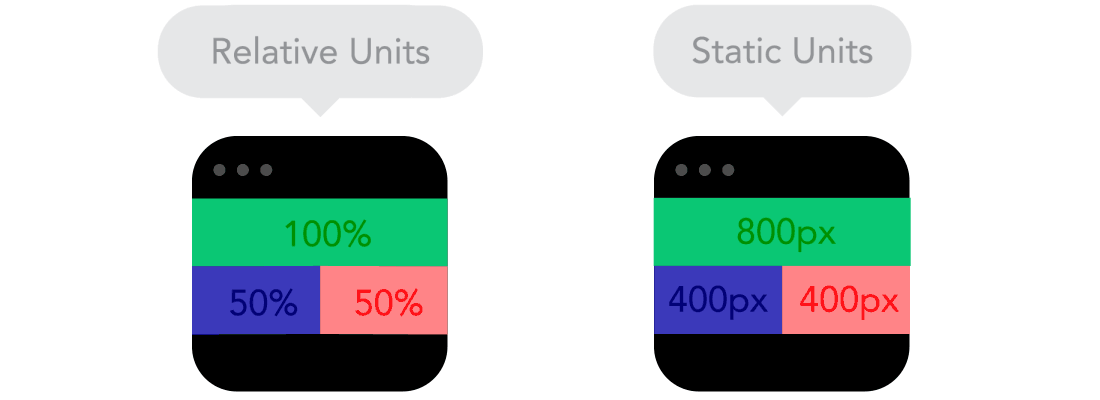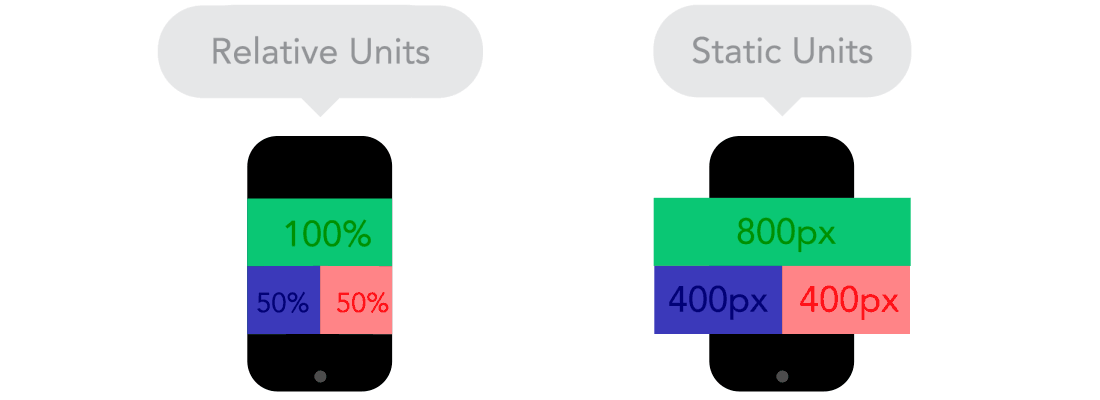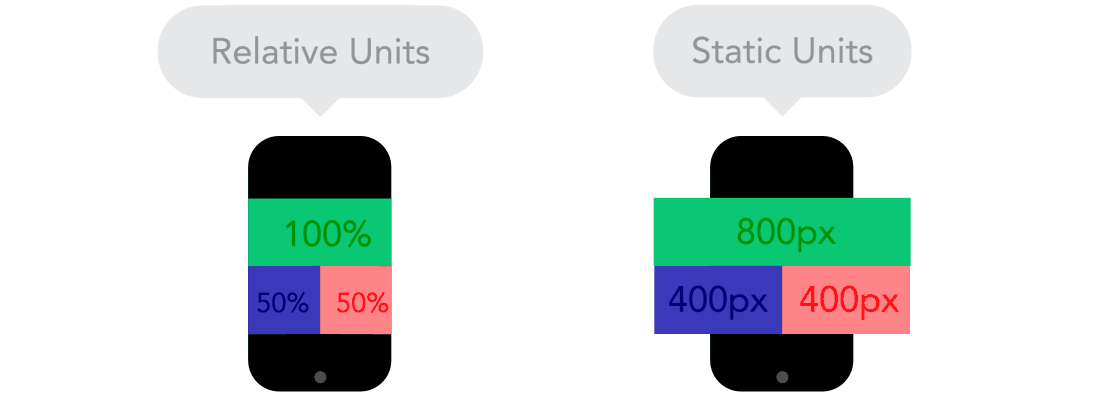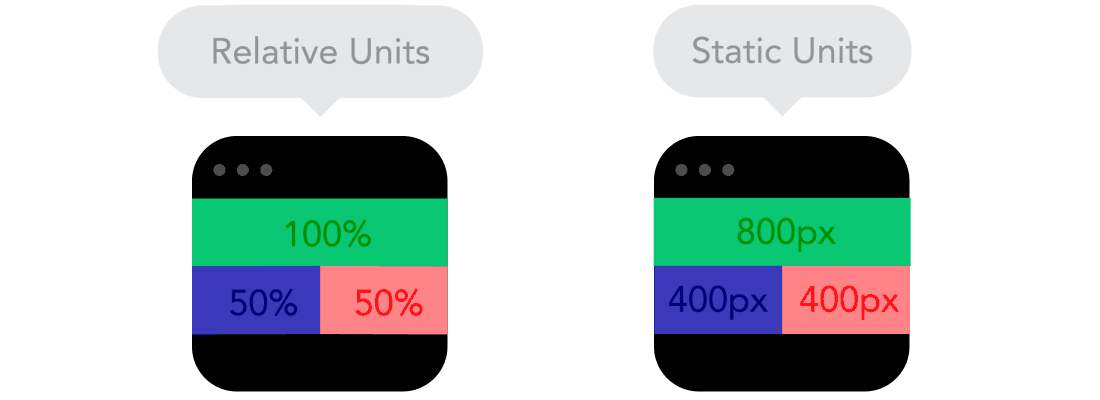 Breakpoints
Breakpoints 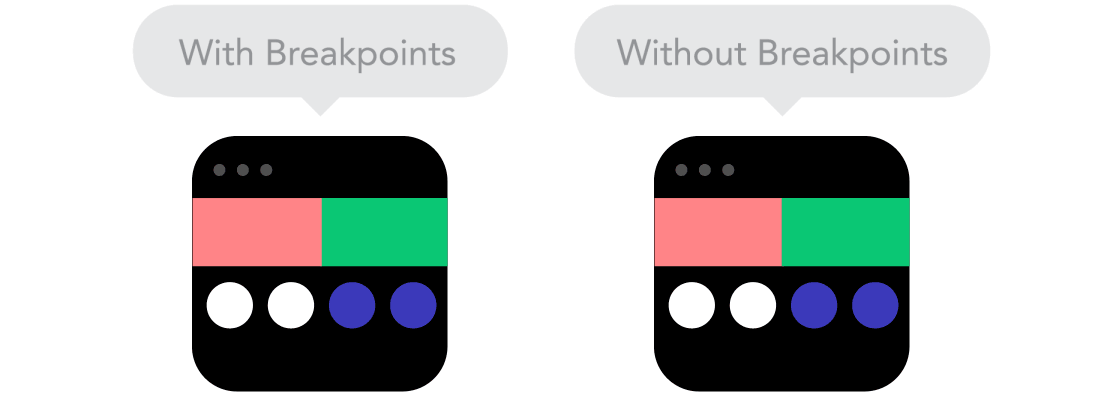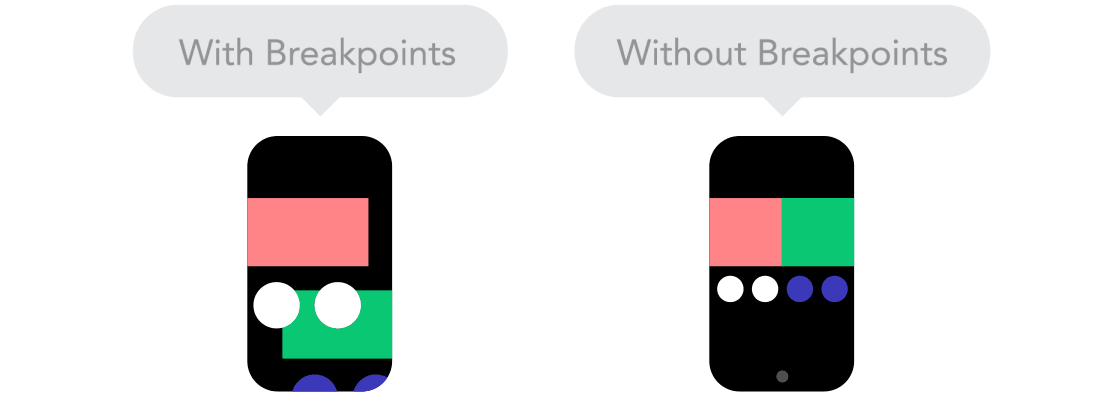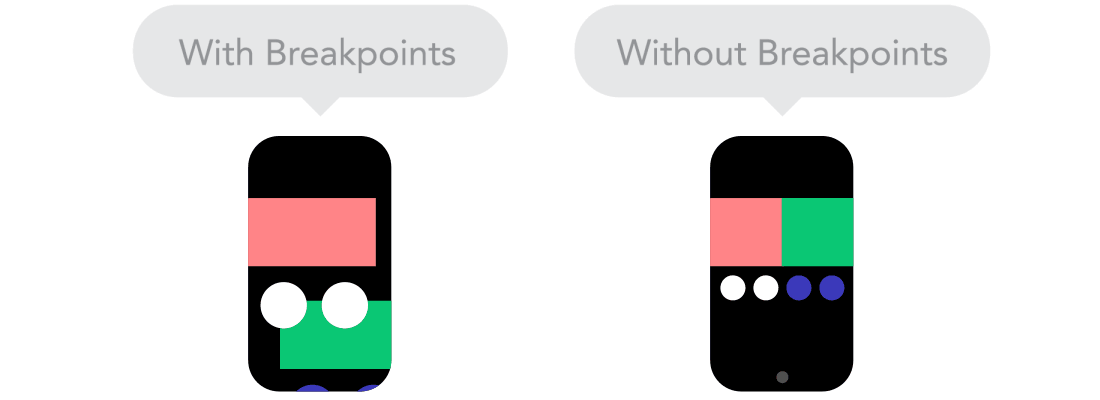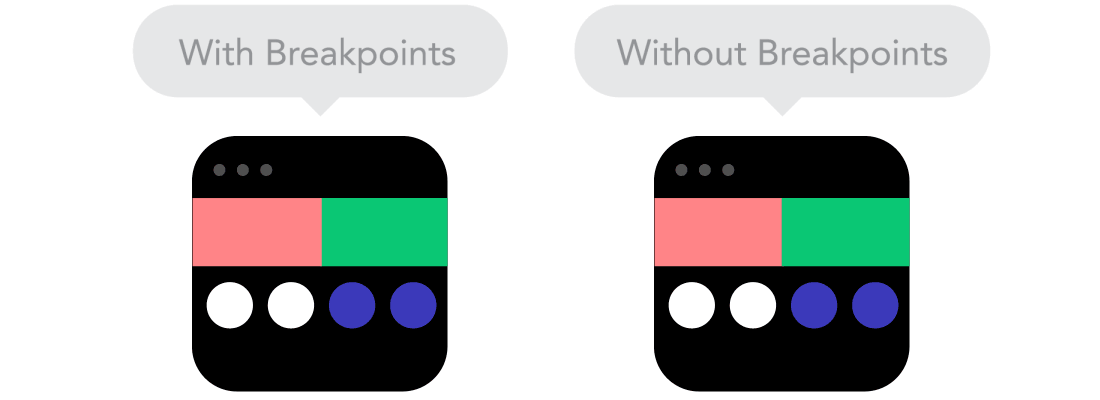 Max and Min
Max and Min 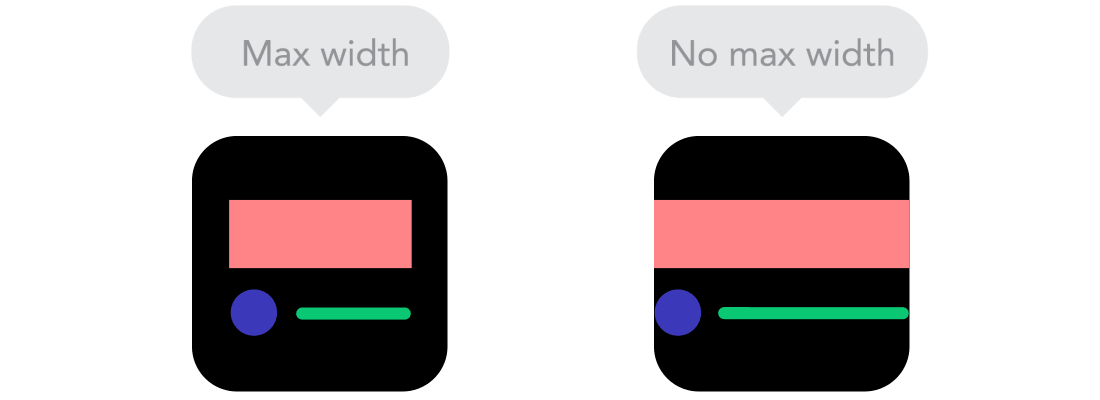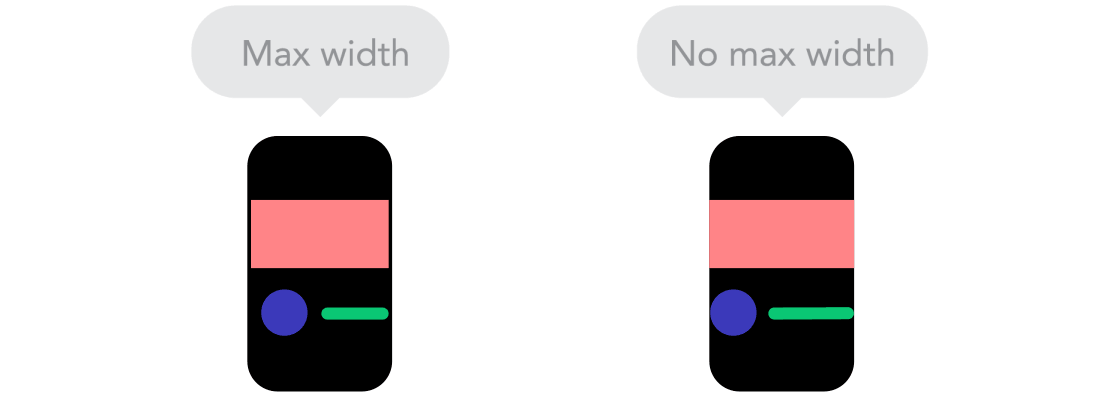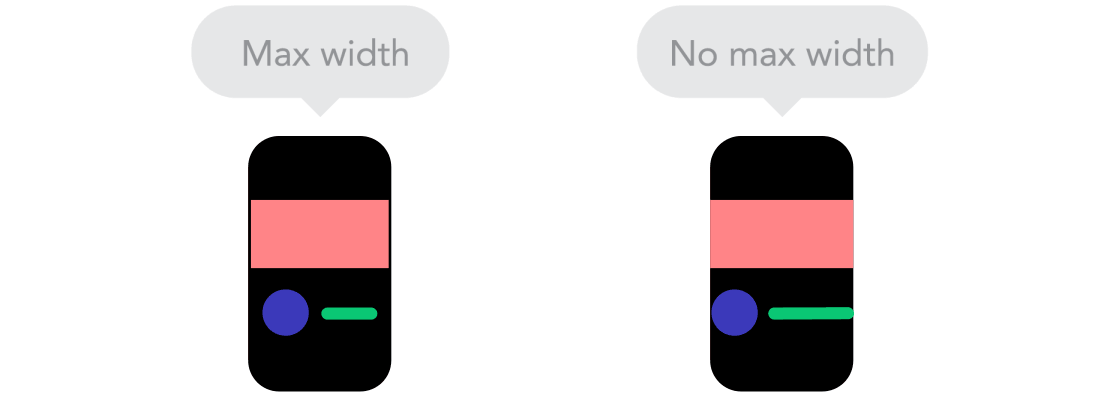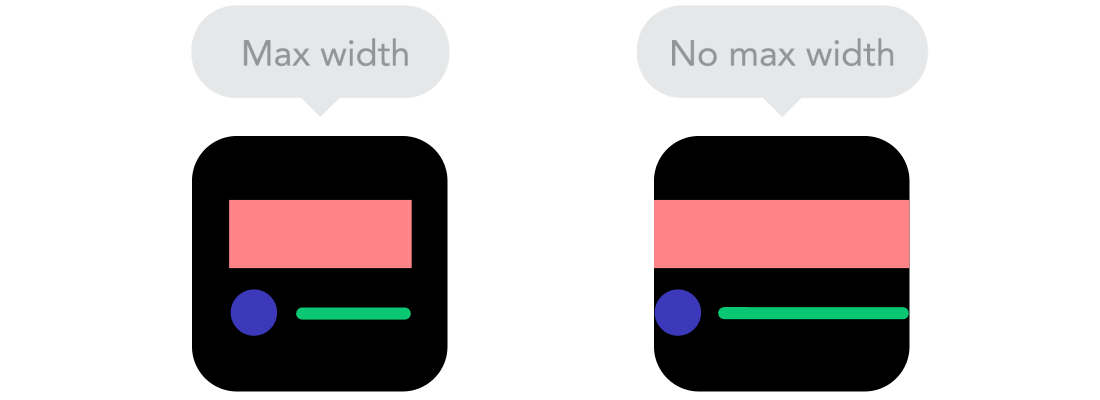 Mobile vr Desktop
Mobile vr Desktop  Webfonts
Webfonts  Image vs Vectors
Image vs Vectors  nach alle den Beispielen mit den Bildern wissen Sie jetzt womit ich meine Brötchen verdiene ;) Den kompletten Artikeln zu dem Thema finden sie hier auf
nach alle den Beispielen mit den Bildern wissen Sie jetzt womit ich meine Brötchen verdiene ;) Den kompletten Artikeln zu dem Thema finden sie hier auf 
 96’ist was noch schlimmeres als Gif Bilder in unser Entwicklerleben gekommen, nämlich FLASH…
96’ist was noch schlimmeres als Gif Bilder in unser Entwicklerleben gekommen, nämlich FLASH…